开源工具专题-04 Atlassian Crowd部署备份及迁移
- 开源工具
- 2024-05-29
- 139热度
- 0评论
开源工具专题-04 Atlassian Crowd部署备份及迁移
注:
- 本教程由羞涩梦整理同步发布,本人技术分享站点:blog.hukanfa.com
- 转发本文请备注原文链接,本文内容整理日期:2024-05-29
- csdn 博客名称:五维空间-影子,欢迎关注
1 安装部署
1.1 制作镜像
注:官方镜像也是可以用的,但这里需要做些定制操作所以干脆自行制作镜像
- 操作如下
- 前置环境准备
# 创建目录 mkdir DiyCrowdImage && cd DiyCrowdImage # 下载crwod包 wget https://product-downloads.atlassian.com/software/crowd/downloads/atlassian-crowd-3.7.2.tar.gz # 下载jdk 官网:https://www.oracle.com/cn/java/technologies/downloads/ 链接:https://pan.baidu.com/s/1rEJbDiGD2iwyv6NVxex_Kw?pwd=ud62 # 下载 Atlassian Crack Agent 作者:https://zhile.io/2018/12/20/atlassian-license-crack.html 链接:https://pan.baidu.com/s/1q9XU9o7LUjYC5howh_ZSPg?pwd=20ia # 下载mysql5.7驱动包 官网:https://downloads.mysql.com/archives/c-j/ 5.1.49 链接:https://pan.baidu.com/s/1ulTRJfEmV0X7I8JMueNFsw?pwd=a7cq # 准备完毕,目录下的文件如下所示 DiyCrowdImage/ ├── atlassian-agent.jar ├── atlassian-crowd-3.7.2.tar.gz ├── Dockerfile ├── jdk-8u411-linux-x64.tar.gz └── mysql-connector-java-5.1.49-bin.jarDockerfile
FROM hukanfa/rockylinux:9.3-base-v1.0 # 设置环境变量 ENV crowdData=/data \ crowdHome=/app/crowd \ crowdTomcatHome=/app/crowd/apache-tomcat \ crowdInitConfig=/app/crowd/crowd-webapp/WEB-INF/classes/crowd-init.properties \ crowdVersion=3.7.2 # 创建目录 RUN mkdir -p /app /data # java #ADD jdk1.8.0_77.tar.gz /usr/local/ ADD jdk-8u411-linux-x64.tar.gz /usr/local # crowd ADD atlassian-crowd-{crowdVersion}.tar.gz /app/ # rename RUN mv /app/atlassian-crowd-{crowdVersion} {crowdHome} \ && mv /usr/local/jdk1.8.0_411 /usr/local/jdk # java 全局声明 ENV PATH=/usr/local/jdk/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin # 拷贝破解agent 和 mysql 驱动 COPY atlassian-agent.jar /app/crowd/apache-tomcat/bin/ COPY mysql-connector-java-5.1.49-bin.jar /app/crowd/apache-tomcat/lib/ # 设置 crowd.home RUN echo "crowd.home={crowdData}" >> {crowdInitConfig} # 在声明java参数前插入加载agent的启动配置 RUN sed -ri "/export JAVA_OPTS/i JAVA_OPTS=\"-javaagent:\$CATALINA_HOME\/bin\/atlassian-agent.jar \${JAVA_OPTS}\" "{crowdTomcatHome}/bin/setenv.sh # 卷声明 VOLUME ["/data","/app/crowd/apache-tomcat/conf"] # 工作目录 WORKDIR crowdTomcatHome # 端口 EXPOSE 8095 # 启动 CMD ["bin/catalina.sh", "run", "@"]- 构建镜像
# 此镜像已经同步推送到hub.docker.com,可直接拉取 docker build -t hukanfa/crowd:3.7.2-agent-mysql-v1.0 .- 创建容器
### 宿主机是 centos 直接执行以下命令 docker run -itd --privileged=true -p 8095:8095 --name crowd hukanfa/atlassian-crowd:3.7.2-agent-mysql-v1.0 ### 宿主机是 Rockylinux9.3 需要做些设置 # 路径: /usr/lib/systemd/system/docker.service 增加 --default-ulimit nofile [Service] Type=notify ExecStart=/usr/bin/dockerd --default-ulimit nofile=65535:65535 -H fd:// --containerd=/run/containerd/containerd.sock ExecReload=/bin/kill -s HUP $MAINPID # 重载配置 systemctl daemon-reload # 重启docker服务 systemctl restart docker # 最后执行下面命令 docker run -itd --privileged=true -p 8095:8095 --name crowd hukanfa/atlassian-crowd:3.7.2-agent-mysql-v1.0- 访问
http://ip:8095,出现以下界面说明镜像制没问题
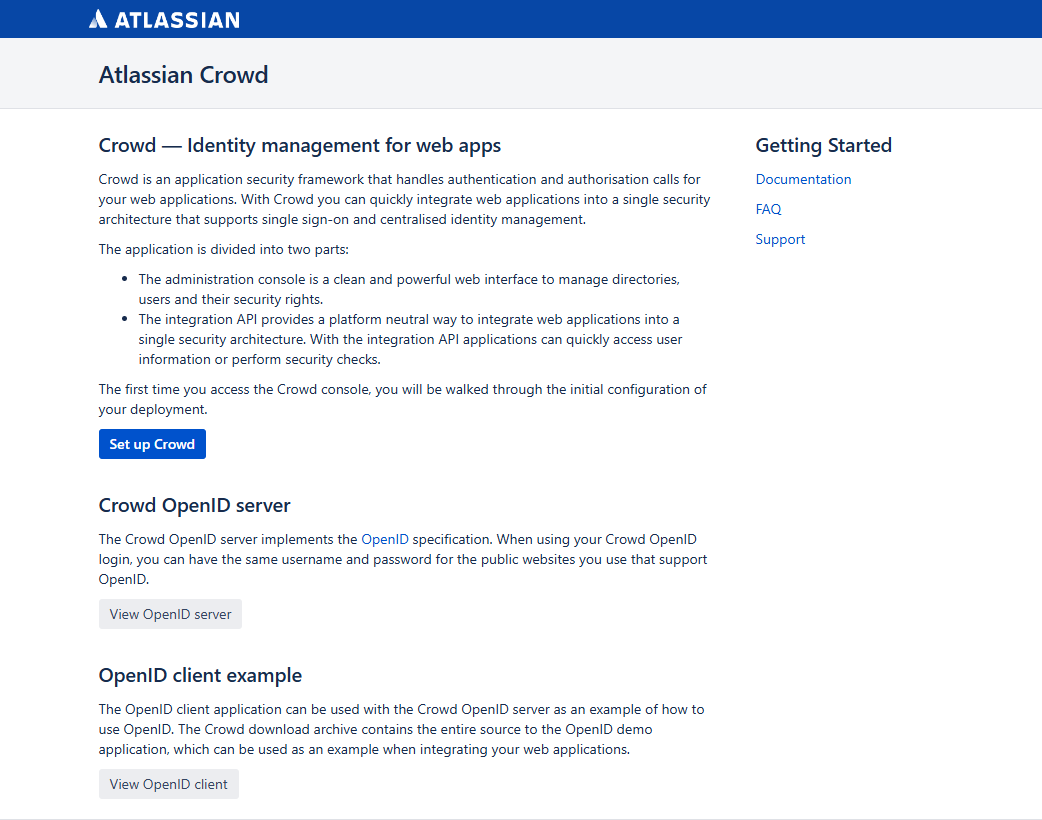
1.2 创建容器
- 操作如下
docker-compose.yaml
version: '3' services: confluence: image: hukanfa/atlassian-crowd:3.7.2-agent-mysql-v1.0 container_name: crowd-srv user: root privileged: true restart: unless-stopped environment: - TZ=Asia/Shanghai ports: - "8095:8095" volumes: - ./data:/data - ./webConf:/app/crowd/apache-tomcat/conf- 拷贝文件
# 创建临时容器 docker run -itd --privileged=true -p 8095:8095 --name crowd hukanfa/atlassian-crowd:3.7.2-agent-mysql-v1.0 # 进入容器 docker exec -it crowd /bin/bash # 打包配置目录 tar -zcvf conf.tar.gz ./conf/ # 另开窗口,拷贝到外面 docker cp crowd:/app/crowd/apache-tomcat/conf.tar.gz ./ # 解压 tar -zxvf conf.tar.gz # 重命名 mv conf webConf- 创建容器
docker-compose up -dmysql5.7
# mysq请自行部署,提供5.7容器方式部署demo下载链接,解压运行即可 https://pan.baidu.com/s/1bWL03T9q0PwDbUINu4HnOA?pwd=0m1t # my.cnf 文件需加入以下配置 [mysqld] ... transaction-isolation = READ-COMMITTED # 创建用户及数据库并授权,crowd 此版本只支持 utf8 格式 CREATE USER 'crowd'@'%' IDENTIFIED BY 'UxqibGbgx3'; create database crowd CHARACTER SET utf8 COLLATE utf8_bin; GRANT ALL ON crowd.* TO 'crowd'@'%'; flush privileges;
1.3 初始配置
- 操作如下
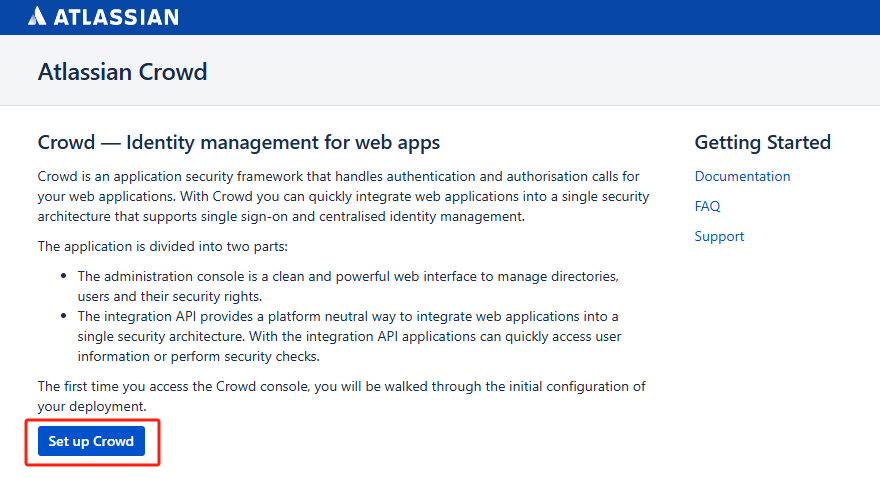
- 访问
http://ip:8095,点击 Set up Crowd
- 复制 Server ID
# Server ID B8VY-UDPW-7NRD-1R6H # 获取 License_key docker exec -it crowd-srv java -jar /app/crowd/apache-tomcat/bin/atlassian-agent.jar \ -p crowd \ -m hukanfa@example.com \ -n crowd_license \ -o https://www.hukanfa.com \ -s B8VY-UDPW-7NRD-1R6H # 替换为 Server ID # 将生成的 license 粘贴到页面的文本框中 AAABlQ0ODAoPeJxtkU+PmzAQxe/+FEg9ViQYCAmRLG0WiJYq5A8k2eZUedlJcBcMtQ0s/fQlCblUK /niGc97P7/5FpVci2inmYaGnbntzk1X85J9fzdt5AmgipXcpwrItaIbE900UNDQvL51yJnmEpAPM hWsulUOPGcFU/Cu5SwFLkF767RMqUrOx+O/GcthxEq0ERfKmbyLPLpt246y+oPyMx2lZYFSUbbvo 9VdZt9VsKYFEG8TRUHshYvV8CBRVCgQA4tXckVTFUSU5WRQe4JPWlS981V1wHqhMiORZ3jLnfds8 fZPieVlcZz4S/YzOf/4HU7G1ml/CQ+LOrPGu/gUFssudrffG7trjp5ZmdaOoN6FK+CUpxB8Vkx0Q 1YzVzem/UEDfeiTVegnwVpf4Sl2sGu7jotte/hCD8waIErUgBIQDYh+4Hl2POkHf/uqT9exr+PYe UEf0B1ByGtq2DGMqTGzLPww+ZpgW4s0oxL+3+LdeV0XbyA254PsZYmOH/E8XEzUQ5MvwIecbyu5S f0aJv8BzejCkzAsAhRxb9+rU5GnV6uaUHhvmZmjvJH3nwIUFbxqhLgFf/XCrc+hXhWVHrLkVnY=X 02jj
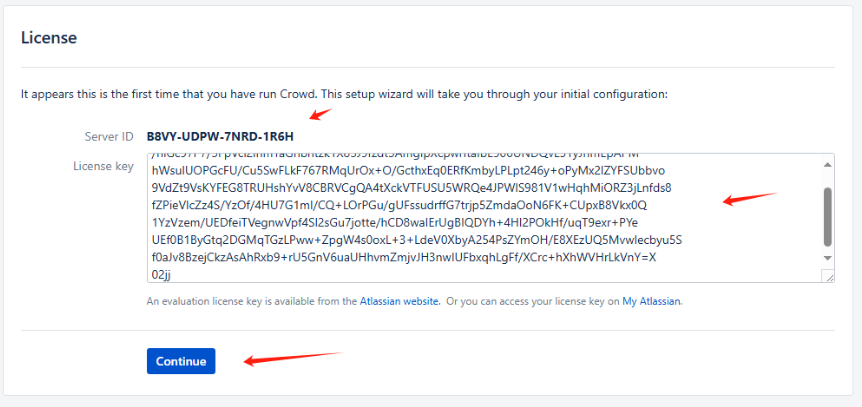
- 下一步,选择 Continue
- 数据库配置
# JDBC_URL 前面配置的账号密码: crowd UxqibGbgx3 jdbc:mysql://192.168.26.5:3307/crowd?autoReconnect=true&characterEncoding=utf8&useUnicode=true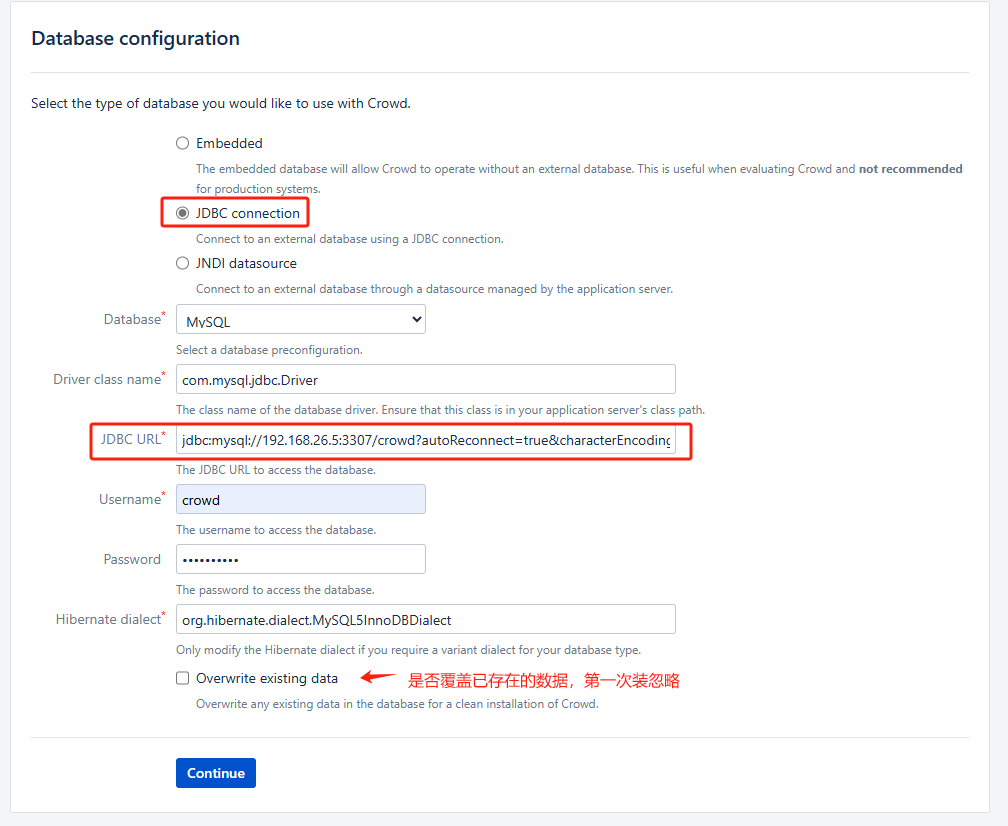
重要:数据库初始化完成后,需要把库和相关表字符集调整成utf8mb4### 目的:支持带有表情包的用户名称,兼容其他数据源的数据迁移导入而不报错 # 修改数据库字符集 ALTER DATABASE crowd CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci; # 修改用户表字符集 ALTER TABLE cwd_user CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;- 下一步:访问设置
- 管理员账号密码设置
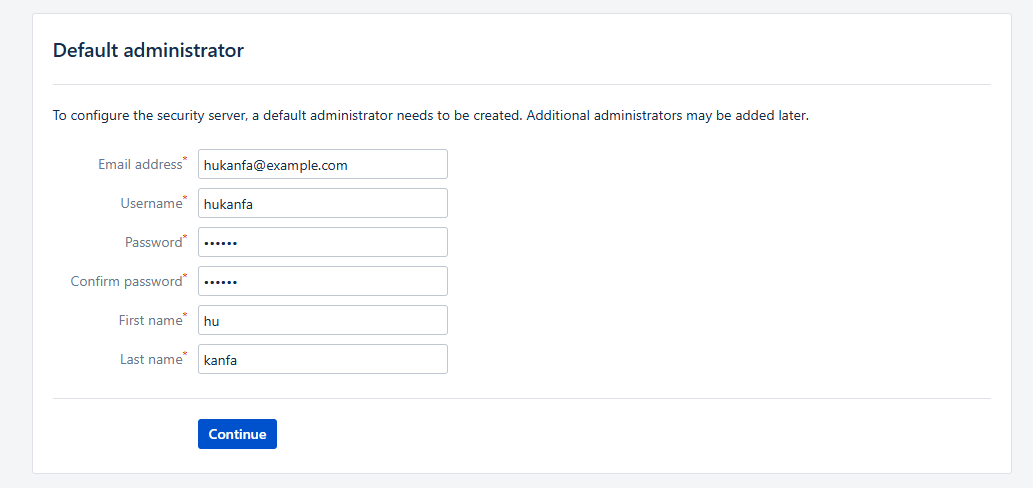
- 下面直接点继续
- 以上所有配置完成会跳转到登录界面,至此,初始配置已完成
- 访问
1.4 Jvm管理(可选)
- 说明
- 本节主要介绍如何手动管理
crowd(tomcat)的jvm大小 - 也可忽略,使用默认配置即可
- 本节主要介绍如何手动管理
- 操作如下
setenv.sh调整
# 容器内路径: /app/crowd/apache-tomcat/bin/setenv.sh ,主要是前三行 jvmXms={JVM_TOMCAT_XMS:=128m} jvmXmx={JVM_TOMCAT_XMX:=512m} JAVA_OPTS="-Xms{jvmXms} -Xmx{jvmXmx} -Dfile.encoding=UTF-8 JAVA_OPTS" JAVA_OPTS="-javaagent:CATALINA_HOME/bin/atlassian-agent.jar {JAVA_OPTS}" export JAVA_OPTS # set the location of the pid file if [ -z "CATALINA_PID" ] ; then if [ -n "CATALINA_BASE" ] ; then CATALINA_PID="CATALINA_BASE"/work/catalina.pid elif [ -n "CATALINA_HOME" ] ; then CATALINA_PID="CATALINA_HOME"/work/catalina.pid fi fi export CATALINA_PIDdocker-compose.yaml
version: '3' services: confluence: image: hukanfa/atlassian-crowd:3.7.2-agent-mysql-v1.0 container_name: crowd-srv user: root privileged: true restart: unless-stopped environment: - TZ=Asia/Shanghai - JVM_TOMCAT_XMS="500m" - JVM_TOMCAT_XMX="2000m" ports: - "8095:8095" volumes: - ./data:/data - ./webConf:/app/crowd/apache-tomcat/conf - ./setenv.sh:/app/crowd/apache-tomcat/bin/setenv.sh- 查看调整
[root@hukanfa crowd]# docker top crowd-srv
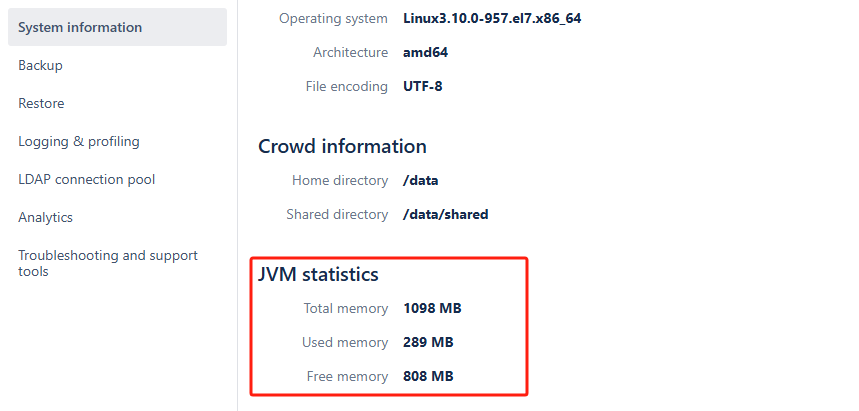
- 界面
System Information显示的 JVM statistics 也相应变化
2 数据备份
- 说明
- Crowd 是账号统一管理及认证平台,其数据安全必须得到可靠保障
- Crowd 数据备份有2种途径
- 1 界面设置定时备份规则,会生成
.xml格式的备份文件 - 2 数据库载体的备份,不管是用 hsqldb 还是 mysql 都应做相应的备份措施
- 操作如下
- 路径:右上角小齿轮 > Backup
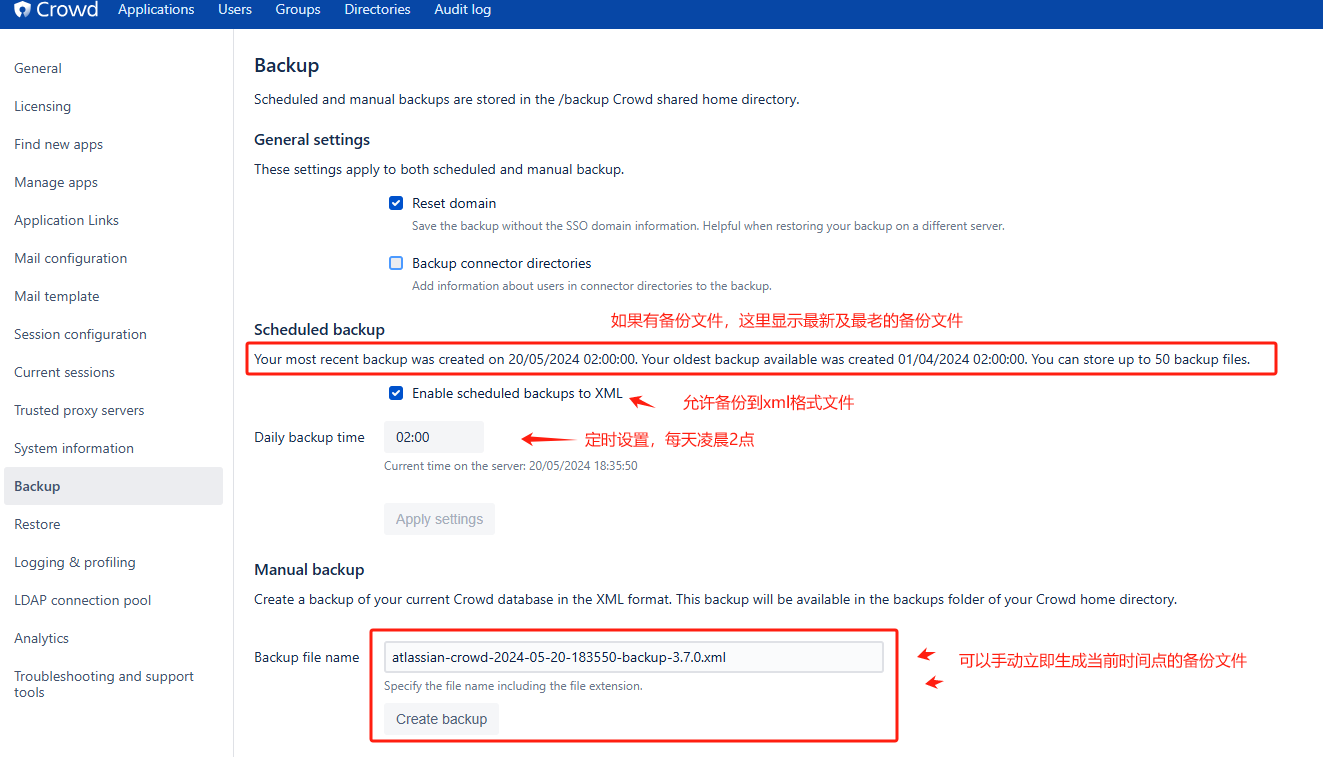
- 备份文件存放路径
# 最多保留50份备份 /data/shared/backups
3 数据迁移&恢复
- 说明
- Crowd 支持通过导入备份的xml格式文件进行数据迁移或恢复
数据迁移注意事项说明- 此次将3.7.0版本且数据源是HSQLDB的实例数据迁移到3.7.2版本的mysql
- 若想保持 3.7.0 版本的管理员用户迁移后密码不变,需在新建3.7.2版本实例时,在以下页面设置相同密码
- 在 3.7.2 实例所有设置完成后,到数据库cwd_user表中将该用户的credential字段值记录下来
- 将 3.7.0 实例备份出的xml文件导入到 3.7.2 完成后,再比对导入前和导入后的credential值是否一致,若不一致则用前面记录的值更新导入后的即可
- 其他非以上初始界面添加的用户密码不变,将和 3.7.0 的一致
- 操作如下
- 直接从备份目录中选择指定的备份文件进行恢复
# /home/hukanfa/crowd/data/shared/backups [root@hukanfa backups]# ls atlassian-crowd-2024-05-21-020000-automated-backup-3.7.0.xml- 界面操作恢复操作
# 注意,在4.1.3节初始配置中提到。数据迁移操作需对crowd数据库和cwd_user表字符集先转成utf8mb4先 /data/shared/backups/atlassian-crowd-2024-05-21-020000-automated-backup-3.7.0.xml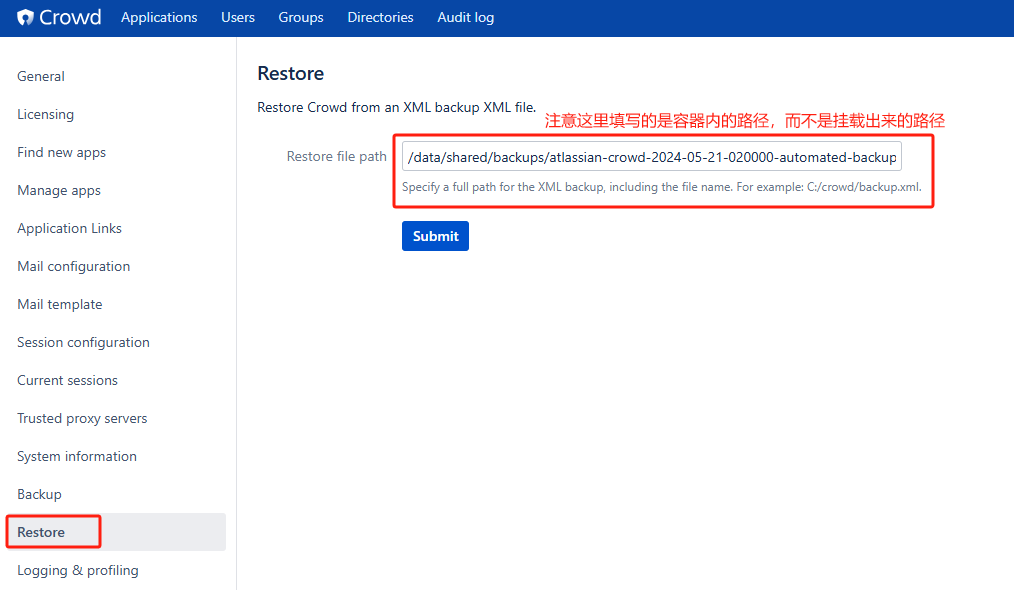
4 交付至 Kubernetes
- 说明
- 请提前安装
nfs服务,用于挂载 crowd 的相关配置文件 - 建议路由不走 Ingress 访问后端,多一层重定向会产生不确定的因素,且不同云平台有不同定制设置
- 若是己方开发的项目可以正常走 Ingress ,因为项目中有啥特殊配置有把握
- 但对于开源项目而言,建议尽量按照最短的有效路径访问到后端服务
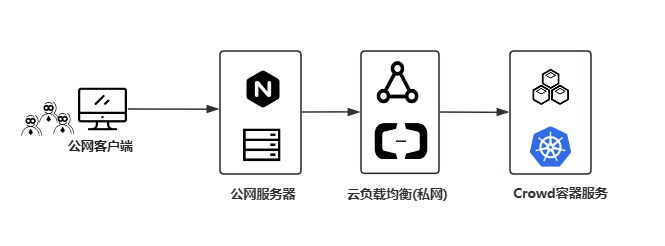
- 本次交付以阿里云为例,访问链路架构图如下所示
- 请提前安装
-
操作如下
- 创建项目目录
mkdir -p /root/devops/crowd-deployment- 创建授权
kubectl apply -f 00-crowd-rbac.yaml,下面的\\要去掉,为了页面能显示---而加的
apiVersion: v1 kind: ServiceAccount metadata: name: crowd namespace: ops \\--- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: crowd rules: - apiGroups: ["extensions", "apps"] resources: ["deployments", "ingresses"] verbs: ["create", "delete", "get", "list", "watch", "patch", "update"] - apiGroups: [""] resources: ["services"] verbs: ["create", "delete", "get", "list", "watch", "patch", "update"] - apiGroups: [""] resources: ["pods"] verbs: ["create", "delete", "get", "list", "patch", "update", "watch"] - apiGroups: [""] resources: ["pods/exec"] verbs: ["create", "delete", "get", "list", "patch", "update", "watch"] - apiGroups: [""] resources: ["pods/log", "events"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["secrets"] verbs: ["get"] \\--- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: crowd namespace: ops roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: crowd subjects: - kind: ServiceAccount name: crowd namespace: ops- 创建 Deployment
kubectl apply -f 02-crowd-deployment.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: crowd namespace: crowd-cluster labels: app: crowd spec: replicas: 1 strategy: rollingUpdate: maxSurge: 50% maxUnavailable: 0 type: RollingUpdate selector: matchLabels: app: crowd template: metadata: labels: app: crowd spec: serviceAccount: crowd imagePullSecrets: - name: vpc-crowd-registry dnsPolicy: None dnsConfig: nameservers: - 192.168.4.251 containers: - name: crowd image: registry-vpc.cn-guangzhou.aliyuncs.com/qlchat-dev/atlassian-crowd:3.7.2-agent-mysql-v1.0 imagePullPolicy: IfNotPresent securityContext: privileged: true env: - name: JAVA_OPTS value: -Duser.timezone=Asia/Shanghai - name: JVM_TOMCAT_XMS value: 2000m - name: JVM_TOMCAT_XMX value: 4000m ports: - name: http containerPort: 8095 resources: limits: cpu: 2000m memory: 4096Mi requests: cpu: 1000m memory: 2048Mi readinessProbe: httpGet: path: / port: 8095 initialDelaySeconds: 30 periodSeconds: 10 timeoutSeconds: 5 successThreshold: 1 failureThreshold: 5 volumeMounts: - name: data mountPath: /app/crowd/apache-tomcat/conf subPath: webConf - name: data mountPath: /app/crowd/apache-tomcat/bin/setenv.sh subPath: bin/setenv.sh - name: data mountPath: /data subPath: data volumes: - name: data nfs: server: 192.168.4.252 path: "/data/nfsDataShare/crowd"- 创建 Service
kubectl apply -f 02-crowd-deployment.yaml
apiVersion: v1 kind: Service metadata: annotations: # 绑定负载均衡实例ID service.beta.kubernetes.io/alibaba-cloud-loadbalancer-id: "lb-7xxxxxxxx7z9s" # 将pod的eni网卡作为负载均衡后端虚拟服务器组成员 service.beta.kubernetes.io/backend-type: "eni" # 负载均衡自动移除不可调度的后端服务 service.beta.kubernetes.io/alibaba-cloud-loadbalancer-remove-unscheduled-backend: "on" # 覆盖监听,仅影响本 Service 管理的端口,不影响该负载均衡上其他服务的监听端口 service.beta.kubernetes.io/alibaba-cloud-loadbalancer-force-override-listeners: "true" # 开启会话保持 service.beta.kubernetes.io/alibaba-cloud-loadbalancer-protocol-port: "http:80" service.beta.kubernetes.io/alibaba-cloud-loadbalancer-sticky-session: "on" # cookie的处理方式,insert:植入Cookie service.beta.kubernetes.io/alibaba-cloud-loadbalancer-sticky-session-type: "insert" # Cookie超时时间 service.beta.kubernetes.io/alibaba-cloud-loadbalancer-cookie-timeout: "1800" name: crowd-svc namespace: crowd-cluster spec: ports: - name: http port: 8095 targetPort: 8095 selector: app: crowd type: LoadBalancernginx配置如下
# nginx 配置如下,proxy_pass 地址为负载均衡(CLB)的ip地址 # 测试的crowd服务 server { listen 80; server_name crowd.hkf56.com; access_log logs/crowd_access.log main; error_log logs/crowd_error.log; location / { proxy_pass http://192.168.11.164:8095; proxy_redirect off; proxy_set_header Host host; proxy_set_header X-Real-IPremote_addr; proxy_set_header X-Forward-For $proxy_add_x_forwarded_for; } }- 关于负载均衡配置说明
1、这里采用Service绑定已有负载均衡的方式,所以先创建负载均衡 2、Service 起来后,会将pod的网卡加入到负载均衡的虚拟后端服务器组,并自动创建对应监听端口 3、即当访问到负载均衡环节时,会直接将请求转发到后端pod服务 4、如果没用这个注解:alibaba-cloud-loadbalancer-force-override-listeners 就需要手动添加和删除监听端口 5、具体配置请看官方文档:https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/add-annotations-to-the-yaml-file-of-a-service-to-configure-clb-instances?spm=a2c4g.11186623.0.0.513f2dbclRbGH7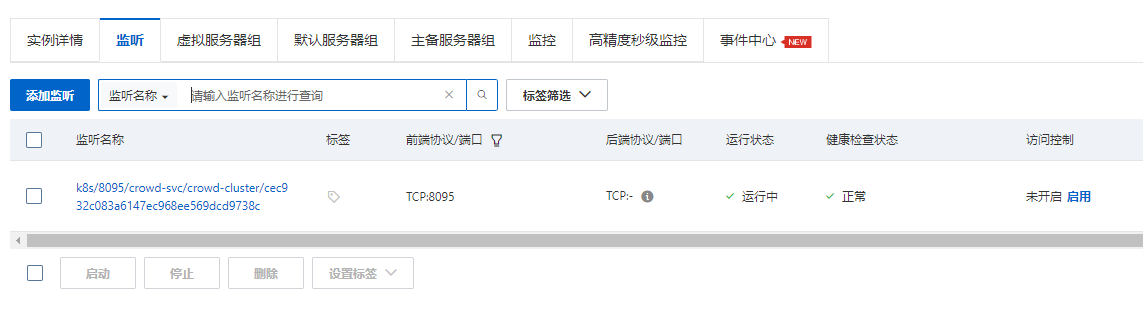
- 上述配置完成并设置公网解析后,即可通过域名
crowd.hkf56.com访问 crowd 服务,如何响应慢不妨cpu给大点